|
Email / CV / Google Scholar / Github |

|
|
|
|
I am a PhD student at the MIT Computer Science & Artificial Intelligence Lab, advised by Prof. Daniela Rus and Dr. Ramin Hasani. I am interested in making deep learning more efficient, particularly by reducing the data requirements of large models. Recently, I have been looking at the dataset distillation problem, and how recent insights into the training dynamics of deep networks can be used to tackle it. Previously, I obtained an MEng and BA in Engineering at the University of Cambridge. There, I worked with Prof. Richard E. Turner on probabilistic models for continual learning. |
|
|
|
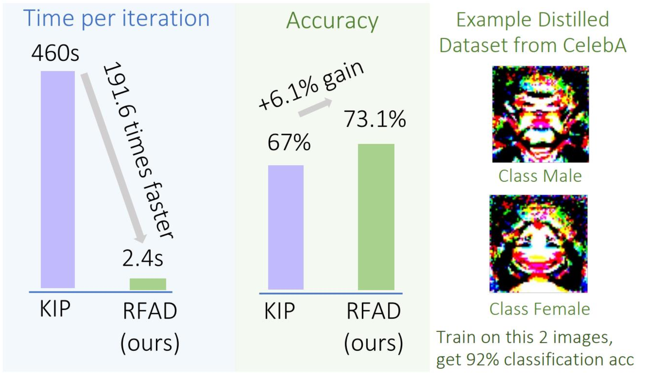
Noel Loo, Ramin Hasani, Alexander Amini, Daniela Rus NeurIPS, 2022 arXiv We propose Random Feature Approximation Distillation (RFAD), a principled approximation scheme for accelerating the prohibitively slow state-of-the-art dataset distillation algorithm, Kernel Inducing Points (KIP). Our algorithm performs as well as KIP but is over 100x faster and requires only a single GPU. |
|
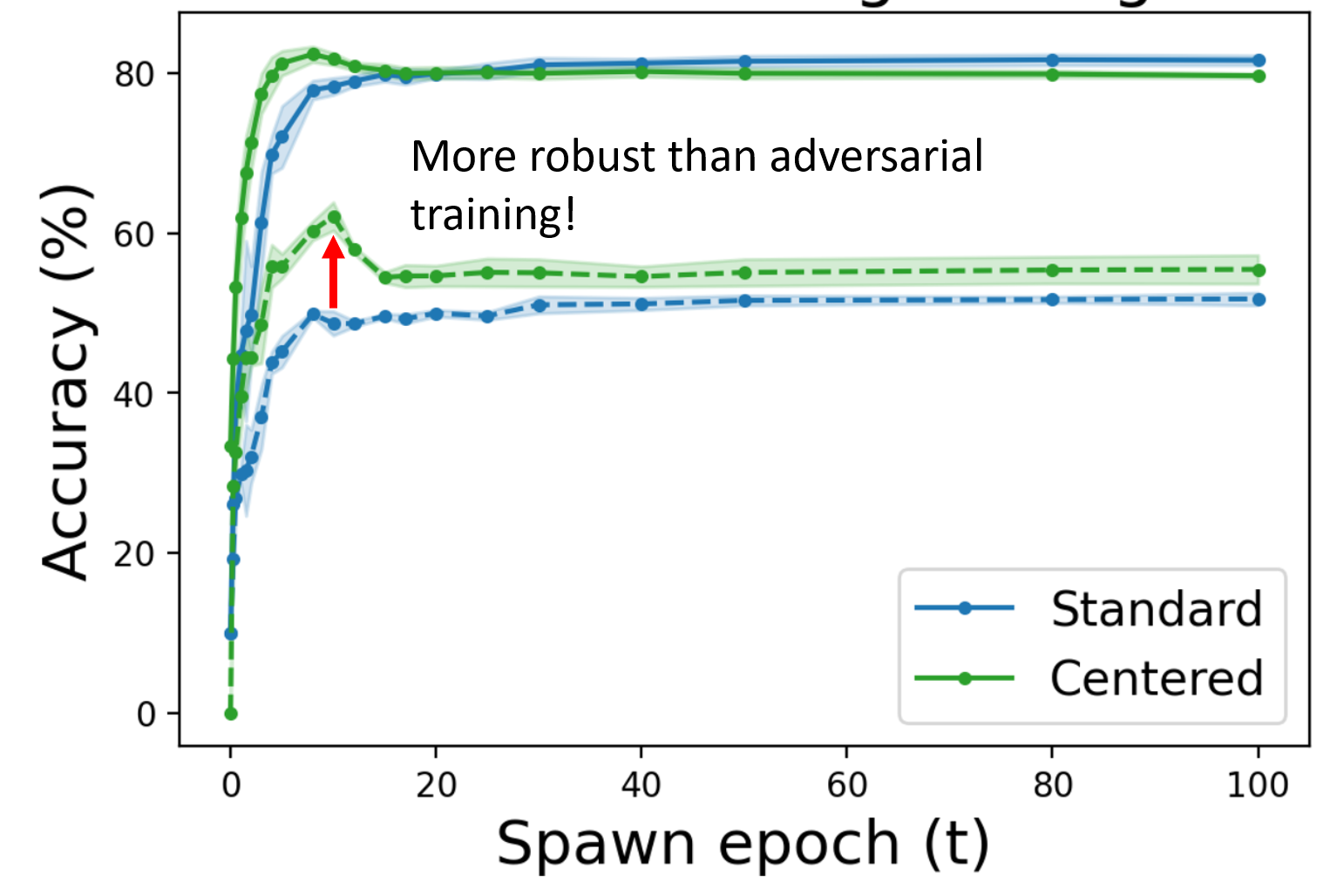
Noel Loo, Ramin Hasani, Alexander Amini, Daniela Rus NeurIPS, 2022 arXiv We empirically study the robustness of the learned finite-width NTK under benign and adversarial training. We find that surprisingly, the benign NTK learns robust features over time, and that linearized training on adversarial NTKs can exceed the robust accuracy of standard adversarial training. |
|
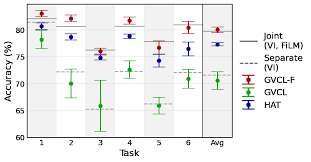
Noel Loo, Siddharth Swaroop, Richard E. Turner ICLR, 2021 arXiv We show that two popular continual learning algorithms, Variational Continual Learning (VCL), and Online-Elastic Weight Consolidation (OEWC), can be generalized into a single unified algorithm, Generalized Variational Continual Learning (GVCL). Additionally, we introduce FiLM layers as an architectural change to combat the over-pruning effect in VCL. |
| Template |